Método más usado por Científico de datos e Ingenieros en Inteligencia Artificial
Publicado en 1999 para estandarizar los procesos de minería de datos.
- informacion@pluralmed.com
- Miami
- Empresas
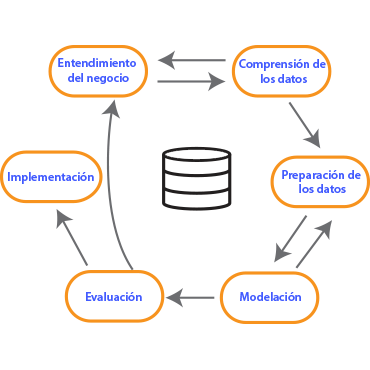
Es una metodología de 6 pasos secuenciales, mismos que pueden usarse de forma circular para hacer mejora continua de algoritmos de predicción.
La combinación flexible de estos pasos permite a los científicos de datos crear algoritmos predictivos de forma más confiable.
Todos los proyectos comienzan con un buen entendimiento de las necesidades del cliente. Los proyectos de AI no son la excepción a esta regla y la metodología CRISP-DM reconoce este punto como algo muy relevante.
El primer paso de la fase I es entender exaustivamente el objetivo del cliente y que desea obtener desde una perspectiva de negocio
Determinar los recursos disponibles, requerimientos del proyecto, riesgos y contingencias, y conducir un análisis costo beneficio.
Debemos determinar como sería un caso de éxito desde el punto de vista de la explotación de los datos.
Determinar tecnologías y herramientas que serán usadas en cada fase del proyecto. Con base en esto generar un plan de trabajo.
Recopilar los datos necesarios y cargarlos en las herramientas de análisis si fuera necesario.
Examinar la colección de datos generando un directorio con el significado de los mismos. Posteriormente verificar formato, cantidad de records e identidades de los campos. Es importante la verificación de datos nulos y su tratamiento.
Se deberá profundizar en los datos, para esto se hacen extracciones, visualización, identificación de relaciones entre variables.
Basados en el EDA podremos ver rápidamente que tan limpios y completos se encuentran los conjuntos de datos. Los problemas de calidad de datos son documentados para poder mejorar los modelos de IA.
Determinar que conjuntos de datos serán usados y documentar las razones por las cuales se incluye o excluye un dato.
En muchas ocaciones esta es una labor muy larga. Sin ella, podría obtener basura en los resultados. Las practicas mas usadas durante esta sección son remover datos con errores, corregir datos e imputar datos, ya sea de forma lógica o sintética.
Derivación de nuevos atributos que sean de ayuda. Por ejemplo, obtener el indice de masa corporal de acuerdo al peso y la altura.
Crear nuevos conjuntos de datos al combinar datos de multiples fuentes.
Re formatear los datos si es necesario. Por ejemplo cambiar valores string en numéricos para poder hacer operaciones matemáticas entre ellos.
Determinación de algoritmos a ser probados (regresiones, redes neuronales, algoritmos múltiples relacionados, entre otros).
Dependiendo del tipo de modelo deberemos de separar los datos en conjuntos de datos de entrenamiento, pruebas y validación.
En la construcción del modelo se lleva a cabo programación específica para cada modelo y una sección hipersintonía para afinar los resultados. Esta sección puede ser tardada dependiendo de la cantidad de datos a ser procesados.
Generalmente muchos modelos de AI compiten entre si y el experto deberá evaluar e interpretar los resultados de cada modelo basado en su dominio de conocimiento y en los parámetros predefinidos como criterios de éxito. El diseño de las pruebas de verificación se convierte algo crítico en este punto.
Verificar si los modelos cumplieron con los criterios de éxito para el negocio planteados inicialmente. Seleccionar los que deberíamos aprobar para el cliente.
Realizar una revisión general del trabajo concluido. Verificar que nada se haya pasado por alto y que todos los pasos hayan sido completados. Deberá hacerse una sumarización y corregir si se encontró algo fuera de lo normal.
Basado en las fases anteriores determinar si se puede proceder a implementar, iterar sobre el mismo proyecto o iniciar uno nuevo.
Desarrollar y documentar un plan para la implementación del modelo seleccionado.
Desarrollar un plan de monitoreo y mantenimiento para evitar problemas durante la operación del modelo.
El equipo del proyecto documenta un sumario del mismo el cual incluye la presentacion final del resultado del procesamiento de datos.
Se conduce una retrospectiva del proyecto acerca de lo que se realizó bien, lo que se puede mejorar y como realizar la mejora en el futuro.